
Research
Current Research
Machine Learning for Autonomic System Operation in the Heterogeneous Edge-Cloud Continuum (MLSysOps)
We are working on the design, implementation and evaluation of a complete framework for autonomic end-to-end system management across the full cloud-edge continuum. Our framework employs a hierarchical agent-based AI architecture to interface with the underlying resource management and application deployment/orchestration mechanisms of the continuum. Adaptivity is achieved through continual ML model learning in conjunction with intelligent retraining concurrently to application execution, while openness and extensibility is supported through explainable ML methods and an API for pluggable ML models. Flexible/efficient application execution on heterogeneous infrastructures and nodes will be enabled through innovative portable container-based technology.
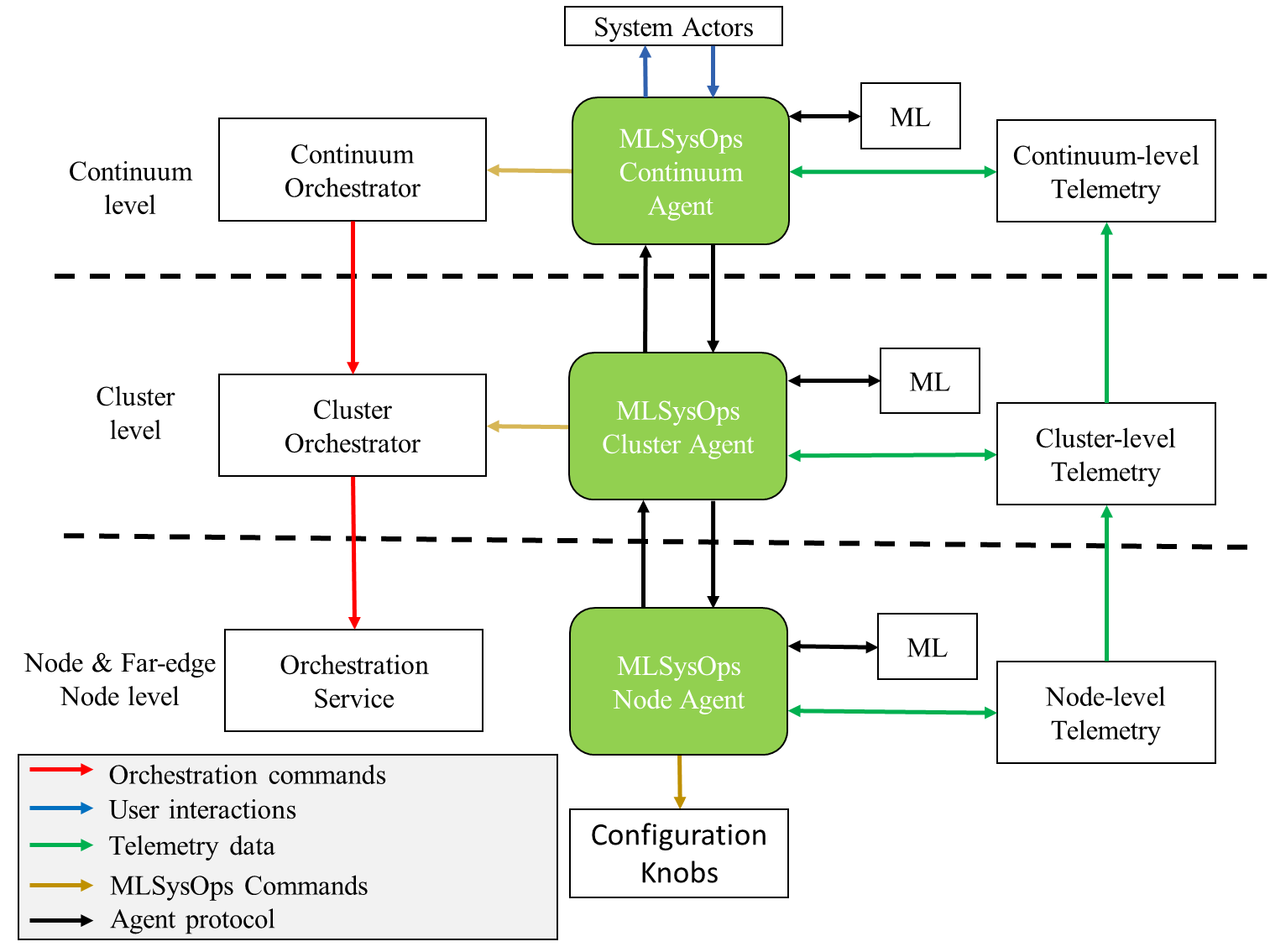
Energy efficiency, performance, low latency, efficient, resilient and trusted tier-less storage, cross-layer orchestration including resource-constrained devices, resilience to imperfections of physical networks, trust and security, are key elements of this work addressed using ML models. The framework architecture disassociates management from control and seamlessly interfaces with popular control frameworks for different layers of the continuum. The framework is evaluated using research testbeds as well as two real-world application-specific testbeds in the domain of smart cities and smart agriculture, which is also used to collect the system-level data necessary to train and validate the ML models, while realistic system simulators will be used to conduct scale-out experiments. (Github)
In the context of this work, we presented LACE-RL, a latency-aware and carbon-efficient management framework that formulates serverless pod retention as a sequential decision problem. LACE-RL uses deep reinforcement learning to dynamically tune keep-alive durations, jointly modeling cold-start probability, function-specific latency costs, and real-time carbon intensity. Using the Huawei Public Cloud Trace, we show that LACE-RL reduces cold starts by 51.69% and idle keep-alive carbon emissions by 77.08% compared to Huawei’s static policy, while achieving better latency–carbon trade-offs than state-of-the-art heuristic and single- objective baselines, approaching Oracle performance.
In this line of work we have also focused on efficient on-device DNN training. We proposed the TMModel, a performance model that captures the impacts of memory, and especially the texture cache, on the performance of embedded GPUs (e.g. in high-end cell phones) for different memory access patterns. In a follow-up work, this modeling guides compiler-level optimizations for on-device DNN training by quickly characterizing the effects of operator fusion, data layout synthesis, and sub-batch size selection and performing global co-optimization across the entire computational graph. Experimental results show that our methodology consistently outperforms baselines, achieving speedups of 1.44×–74.5× over the vendor-optimized CLML kernel library and 8.9×–204× over the MNN framework.
We have also worked on ML inference on FPGAs by introducing DPUconfig, a novel runtime management framework, based on a custom Reinforcement Learning (RL) agent, that dynamically selects optimal DPU (Data Processing Units) configurations by leveraging real-time telemetry data monitoring, system utilization, power consumption, and application performance to inform its configuration selection decisions.
Prior Research
Efficient and Reliable Visual SLAM Architectures
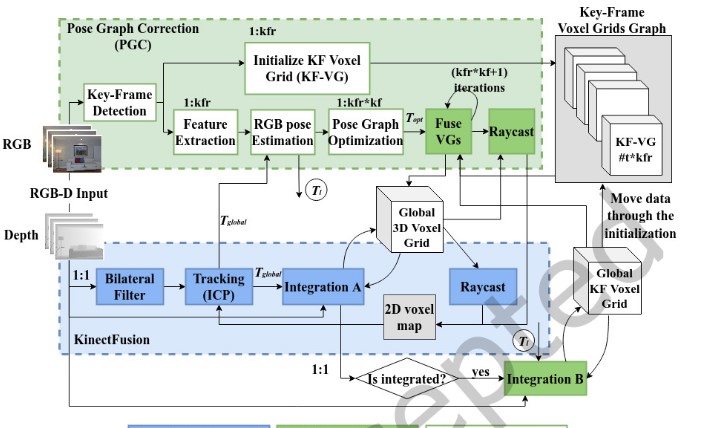
We explore how visual SLAM can be made practical for real-world autonomous systems by balancing two core requirements: performance and reliability. Our research focused on embedded, resource-constrained platforms and presented optimized FPGA/MPSoC-based implementations for dense SLAM, showing how precise and approximate hardware/software optimizations can deliver real-time, low-power performance—reaching more than 30 fps and up to 46× speedup for key kernels—while preserving tracking quality. We introduced PG-SLAM, an extension to KinectFusion algorithm that helps a humanoid robot recover its pose when the baseline KinectFusion tracking system fails. The pose graph optimization phase is very computationally expensive limiting real-time PG-SLAM performance. Hence, we proposed numerous approximations to reduce computation requirements and we explored the architecture of multiple HW/SW FPGA designs that implement approximate versions of PG-SLAM. We showed that even though approximations are necessary to achieve real-time operation, they need to be applied carefully to avoid large numbers of untracked frames. We provided a practical framework for building high-performance, energy-efficient, and robust visual SLAM systems for next-generation robotics and edge AI applications. (TECS’2023)
Universal Micro-Server Ecosystem by Exceeding the Energy and Performance Scaling Boundaries (Uniserver)
This research explored a new generation of energy-efficient micro-server systems for data-intensive and distributed computing. A key part of its vision was significance-based computing, an approach that treats data and computations according to how critical they are, allowing the system to apply stronger protection where it matters most and relax constraints where small errors are tolerable. Significance-based computing turns uncertainty from a liability into a managed resource, enabling aggressive power savings and better performance-per-watt without treating every bit, core, or software structure as equally critical.
We also presented a practical way to make modern multicore processors more energy efficient by safely reducing CPU voltage below conservative factory-set margins. Focusing on Intel Haswell and Skylake systems, we show that these built-in voltage margins are often larger than necessary in real workloads, and they introduce an Extended Dynamic Voltage Scaling (xDVS) governor that uses performance counters and CPU utilization to predict and apply the minimum safe voltage at runtime. The result is a lightweight, adaptive approach that improves performance-per-watt with up to 42% energy savings on Skylake and 34% on Haswell, while keeping performance overhead negligible—making it especially relevant for servers, HPC platforms, and other power-constrained compute environments. (TPDS’2020) 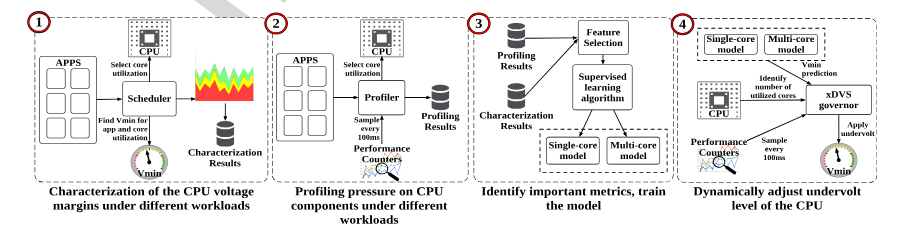
Building on the previous paper’s idea of exploiting conservative hardware margins, we extend the approach from CPUs to DRAM in cloud servers. With RM-DRAM, we demonstrate that relaxing memory operating margins can reduce energy use by up to 34.84% and operating cost by 29.53%, while managing reliability and SLA risks through cost-aware scheduling. (CCGrid’2020)
Significance-based Computing for Reliability and Power Optimization (SCoRPiO)
Hardware manufacturers typically build in substantial safety margins—through voltage guardbands, conservative design rules, and additional protection circuitry—to ensure fault-free operation. Yet much of this built-in redundancy is not always necessary, especially for modern workloads such as multimedia, machine learning, and visualization, where limited imprecision can often be tolerated without noticeably affecting the final outcome. This project explored how to relax strict hardware reliability requirements by developing methods that enable the system and application software to work together in identifying which parts of a program are most critical to output quality and which can better tolerate faults. Using that knowledge, the system can direct computations and data either to low-power but potentially less reliable components or to higher-power, more dependable ones. In this way, the varying significance of different computations is used to support targeted approximate computing and improve overall energy efficiency.
We developed runtime support that sets the supply voltage in a multicore CPU to sub-nominal values to reduce the energy footprint and provide mechanisms to control output quality. The developers specify the significance of application tasks respecting their contribution to the output quality and provide check and repair functions for handling faults (TACO’2017)
We worked on automating the process of identifying which parts of a program can safely tolerate approximation. We combined interval arithmetic and algorithmic differentiation to estimate how strongly inputs and computations affect output quality, then use that information to guide selective approximation. Across a range of benchmarks, the approach closely matches expert choices and achieves 31% to 91% energy savings on a multicore x86 system while maintaining acceptable output quality. (CGO’2016)
Automatic Hardware Generation Using the Streaming Paradigm
The problem of automatically generating hardware modules from a high level representation of an application (aka High Level Synthesis) has been at the research forefront of the EDA research. The challenge is to close the “architectural gap” between the formal specification of a platform system and its architectural synthesis and final implementation. Such a methodology would potentially enable the large pool of software engineers and algorithm IP experts without architectural and hardware expertise to design and implement platform systems, thus dramatically reducing time to market and increase productivity. Our research produced an end-to-end CAD tool that utilizes concepts of the stream and data-parallel paradigms to generate synthesizable co-processors targeting a commercial platform SoC FPGA. We used OpenCL, an industry supported data-parallel programming standard for writing programs that execute on heterogeneous platforms and accelerators comprising CPUs, GPUs and other forms of accelerators. Our architectural synthesis tool, dubbed SOpenCL (Silicon OpenCL), adapts OpenCL into a novel hardware design flow which efficiently maps coarse and fine-grained parallelism of an application onto an FPGA reconfigurable fabric. SOpenCL transforms unmodified OpenCL kernels into hardware accelerators, with computation and memory communication explicitly decoupled for better efficiency and tunability. By combining compiler optimizations with configurable architectural templates, the approach generates accelerators that adapt to application characteristics and performance goals, helping bridge the gap between parallel programming and custom hardware design.
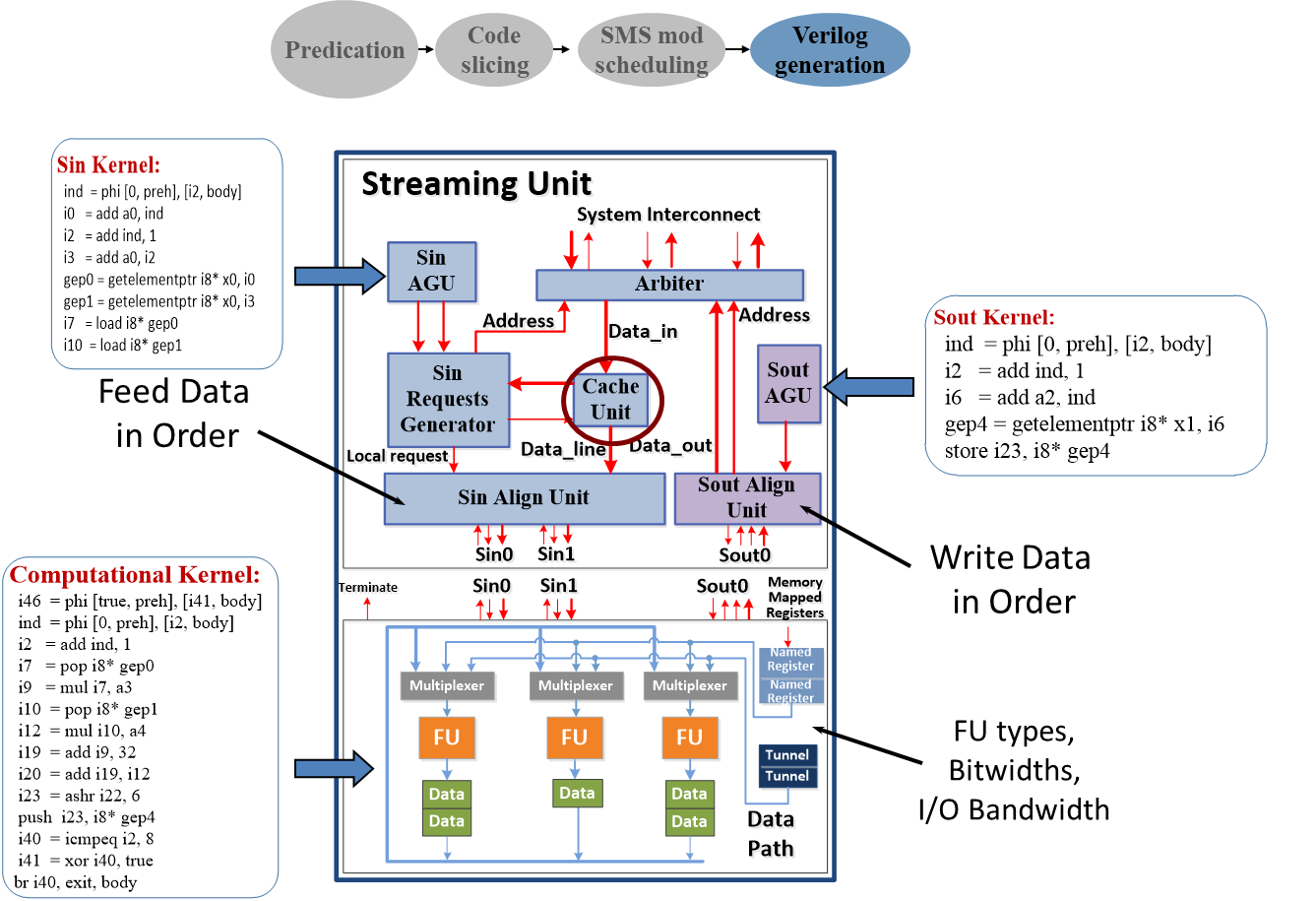
In an earlier version of this research, we worked on an FPGA-based real-time fisheye lens distortion correction system built with automatically generated streaming accelerators. Using a high-level streaming description and the Proteus synthesis tool, we demonstratesd how complex image-processing pipelines can be mapped efficiently to reconfigurable hardware for high-performance embedded vision. (FCCM’2009)
Mapping Algorithms to Parallel and Reconfigurable Platforms
I have spent a great deal of my research in Motorola Labs and the earlier years at the U Thessaly in mapping interesting multimedia and computer vision algorithms onto parallel and hardware accelerator platforms like FPGAs, GPUs, the Cell processor from IBM, and multicore CPUs. Key technical outcomes included the successful implementation of demanding image processing tasks, such as real-time fisheye lens distortion correction (FCCM’2009, ICS’2009, IPDPS’2010) and license plate recognition (RAW’2006), leveraging automatically generated streaming accelerators on FPGAs. The work on non-linear lens-distorted image transformation resulted in fully realized hardware methodologies and also US Patents. Additionally, we have studied the implementation of the AVS video decoding standard across diverse topologies, including heterogeneous dual-core SIMD processors (TCE’2011), and high-performance chip multiprocessors (ICME’2010). Collectively, these technical results demonstrated the efficacy of utilizing the streaming programming paradigm and custom hardware accelerators to satisfy the strict real-time performance requirements of embedded multimedia systems.
Video compression ASIC SoC
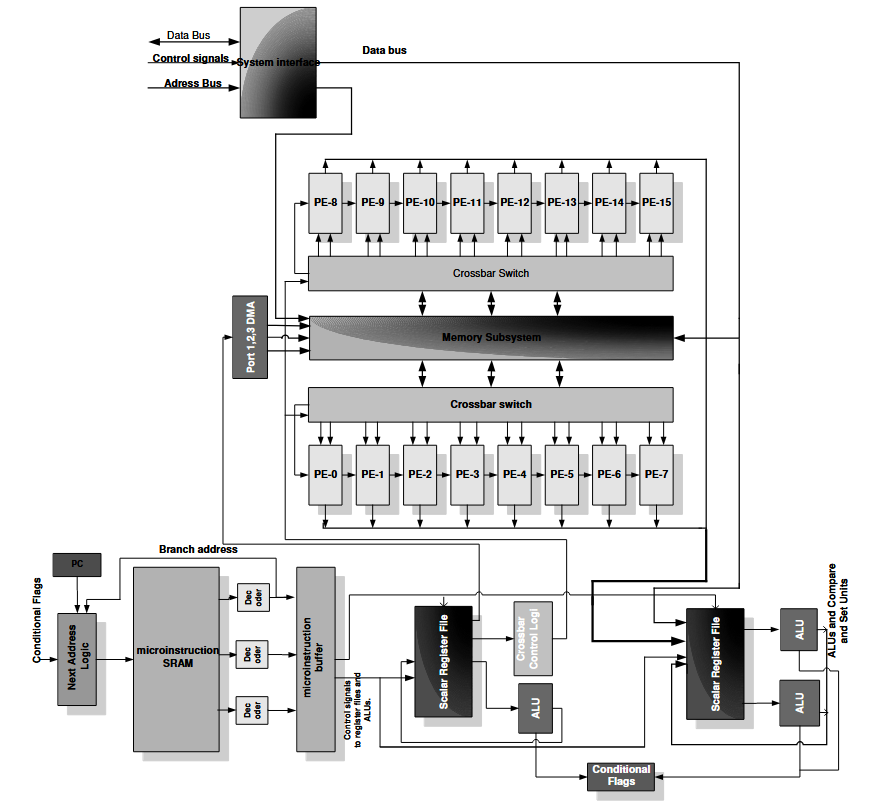
During my tenure at Motorola’s Multimedia Architecture Lab (1999-2007), I worked as one of the architects of highly specialized ASIC designs targeting embedded multimedia applications, and especially programmable MPEG4 video and JPEG image compression. A critical component of this work was the development of a programmable Motion Estimation module, for which I defined a custom Instruction Set Architecture (ISA) and a high-performance vector array unit. This hardware design directly resulted in multiple US Patents, including innovations in real-time motion estimation and virtual memory translation for media acceleration. Furthermore, I served as the chief architect of multiple ASIC chips executing image processing pipelines for next-generation 3G mobile devices.
Low power microarchitectures
My PhD research focused on energy-efficient microarchitecture for high-performance processors, with particular emphasis on reducing the cost of instruction delivery. In this work, I explored how a small, specialized instruction buffer placed between the processor core and the conventional instruction cache could significantly reduce fetch energy by capturing the code regions executed most frequently. We developed this idea through hardware/compiler co-design: the compiler identifies and restructures loop-intensive code so that a compact L0-Cache can service repeated instruction fetches while the main instruction cache remains idle for substantial periods, cutting unnecessary activity in the memory hierarchy (ISLPED’1998). We extended this concept into a more adaptive dynamic cache management framework, where hardware uses branch prediction and confidence estimation to decide at run time which basic blocks should reside in the small L0-Cache, allowing the system to respond to changing execution behavior while preserving performance. This research reflect a broader research theme: combining compiler insight with microarchitectural mechanisms to make aggressive processors more energy-aware, showing that instruction supply can be optimized not just for speed, but also for power efficiency. (ISLPED’1999)